

Comparing Custom LLM Evals with Weave, LangSmith, and Vertex AI for DownPat
Determining Which LLM Evals Package Best Fits Our Needs (For Now)

At DownPat, our need for LLM Evals diverges from the typical “run against a series of benchmarks” strategy. Instead of focusing solely on benchmarks, our use case centers around conversations between users and character-based AI, with an AI coach simultaneously providing feedback. We need robust Evals for:
New Exercise Development: Assessing the quality of LLM responses to determine when new conversational exercises are ready for deployment.
Model Selection: Identifying the most cost-effective and tone-appropriate models.
Continuous Monitoring: Detecting silent model updates that lead to performance degradation or other spontaneous issues.

In my last blog post, I discussed building an Eval pipeline that uses a “LLM-as-a-Judge” system to score and provide feedback on conversion data from our app.
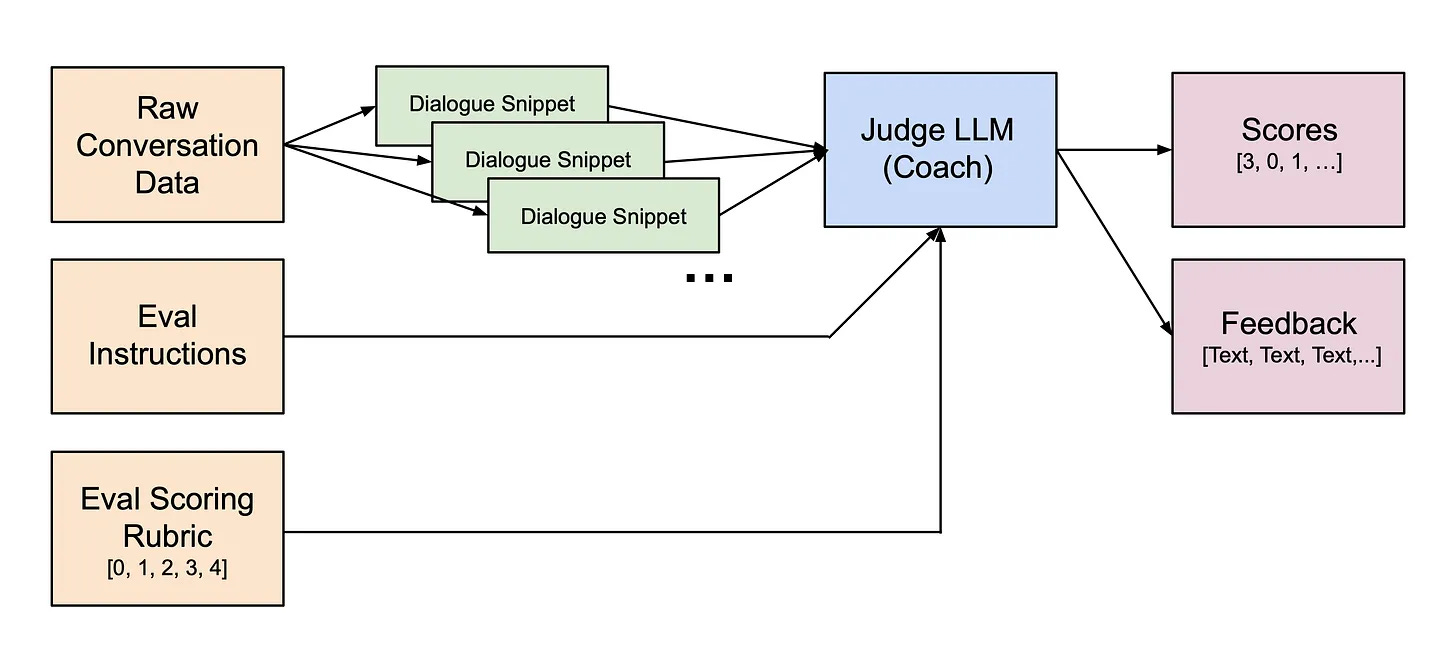
However, this pipeline saves its JSON output files into directories managed within our Evals Python repo – a structure that has become cumbersome for tracking and managing data. Accessing that information also requires manually reading the JSON files or running Python scripts or notebooks to put the results in a more readable form.
Given the rapid advancement in Eval tools since I started this project in April, I decided to evaluate three prominent packages: Weave, LangSmith, and Vertex AI for our specific use case. Although many other platforms exist (e.g., Braintrust, Parea, Datasaur, Arize, etc), time constraints limited my scope for now.
Weave
Weave is a part of Weights & Biases, a leading MLOps platform used by organizations like OpenAI, NVIDIA, Meta, and many more. Weave itself is a standalone package for tracing and evaluating LLM applications.
Features & Development Experience
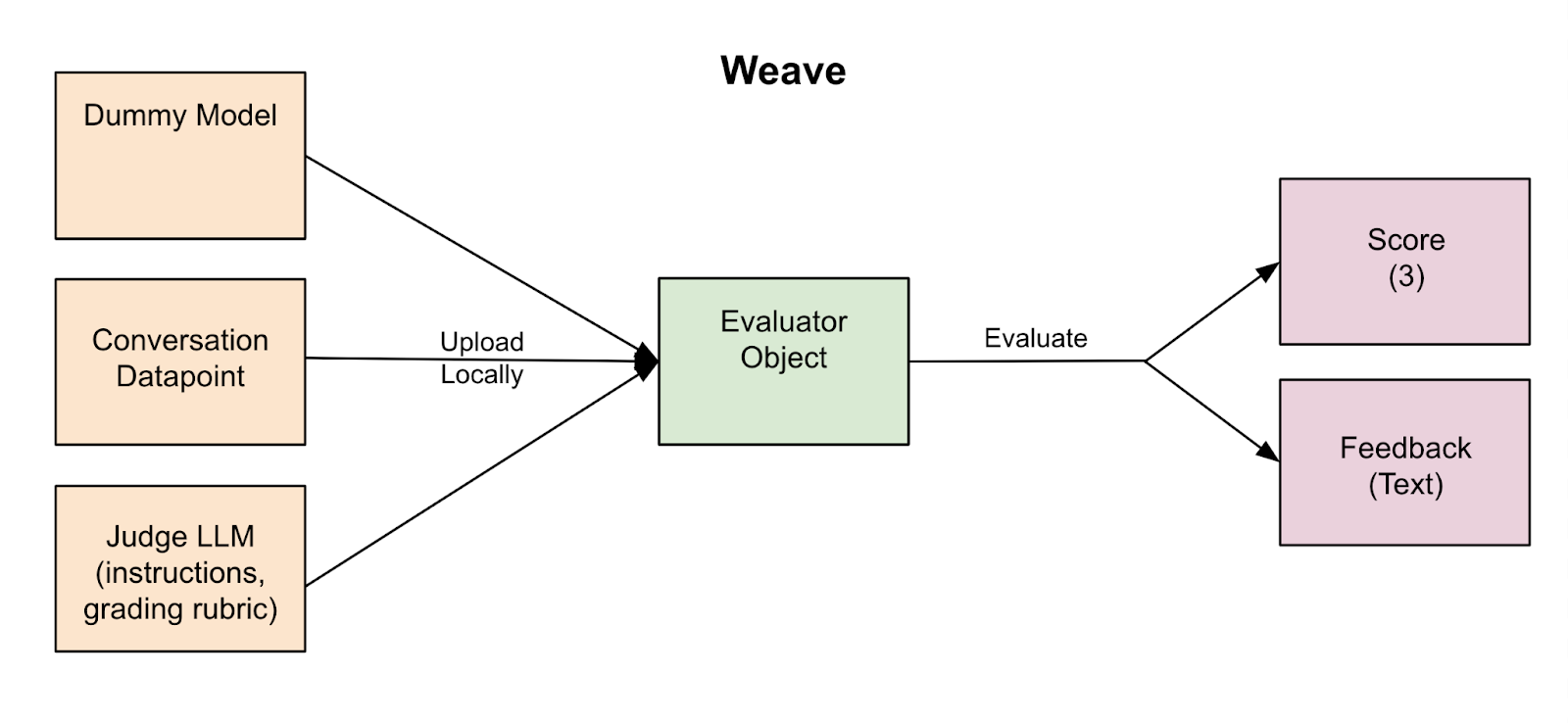
Setup: Weave supports project creation through both its UI and Python SDK. Prompt creation is managed via the SDK, while version control and management happen in the UI. Datasets are uploaded locally during Eval calls.
Customization: Creating a custom scorer class (by extending Weave’s Scorer class) was straightforward for our custom metric, which outputs an object containing fields for a numerical score and text feedback. However, Weave’s Evaluate method is hardcoded for fresh model inference, requiring a workaround. For this I created a dummy model class with a “predict” method that outputs an unused, empty string.
Learning Curve: Development was relatively quick and easy, with a lot of great tutorials and quickstart guides available to work from and thorough documentation.
UI: The UI is intuitive, allowing work to be neatly divided into projects with clear categories for traces, evaluations, prompts, datasets, and models. Eval results are easy to navigate, with customizable columns and expandable trace content.

Pricing
Free Tier: Up to 5 seats, 5GB storage, and core features.
Teams Tier: $50/month/user for up to 10 seats, 100GB storage, and advanced features like alerting and enhanced support.
Enterprise Tier: Custom pricing, custom number of seats, premium support
Given our small size, we’ll likely use the free tier initially and upgrade to the Teams tier as our needs grow.
Verdict
Weave was the easiest platform to develop on, with well-structured tutorials and an intuitive UI. Prototyping was faster and easier compared to LangSmith and Vertex AI.
Langsmith
LangSmith is LangChain’s Eval package, intended for tracing, evaluating, and monitoring LLMs. As a smaller but rapidly growing startup, LangChain is widely used for building LLM applications.
Features & Development Experience
Setup: LangSmith allows prompt creation and management through its Python SDK and UI. Datasets are uploaded via the SDK, with dataset names passed into the Evaluate function.
Customization: Creating a custom scoring function was fairly easy, only requiring that the output of the function be in a supported format such as a dictionary for the score and feedback. Like Weave, it requires a workaround for the Evaluate function’s hard coded model inference assumption (I again use a dummy model returning an empty string).
Learning Curve: Development was initially more challenging due to inconsistencies in the documentation and tutorials. Fortunately, I found a helpful set of YouTube videos that expedited the process with clear examples. Fun fact, when I started at Uber I worked at the desk across from this guy (thanks for the great videos Lance)!
UI: LangSmith organizes work into observability (tracing), evaluation, and prompt engineering categories without project partitioning overhead (maybe because I was using the free version?). While functional, this hierarchy felt less intuitive than Weave’s project-based organization.


Pricing:
Developer (Free Tier): 1 user, 5k traces/month, and core features.
Plus Tier: $39/month/user for up to 10 seats, 10k traces/month and additional support
Startups & Enterprise: Custom pricing, higher trace allowances and premium support
We would need to move to the Plus or Startup service tier to enable multiple people to have access.
Verdict
While LangSmith worked well for prototyping, the platform felt less intuitive than Weave (but better than Vortex), and inconsistent documentation slowed development. Still, it would be a solid choice for our Eval workflows.
Vertex AI
Vertex AI is an Eval package from Google. Well, actually it’s an entire AI platform that can manage prompts, call Gemini and other LLM’s, host/run Python notebooks via Colab and Workbench, and much more, but today I only really care about Evals. And Google is… well, Google.
Features & Development Experience
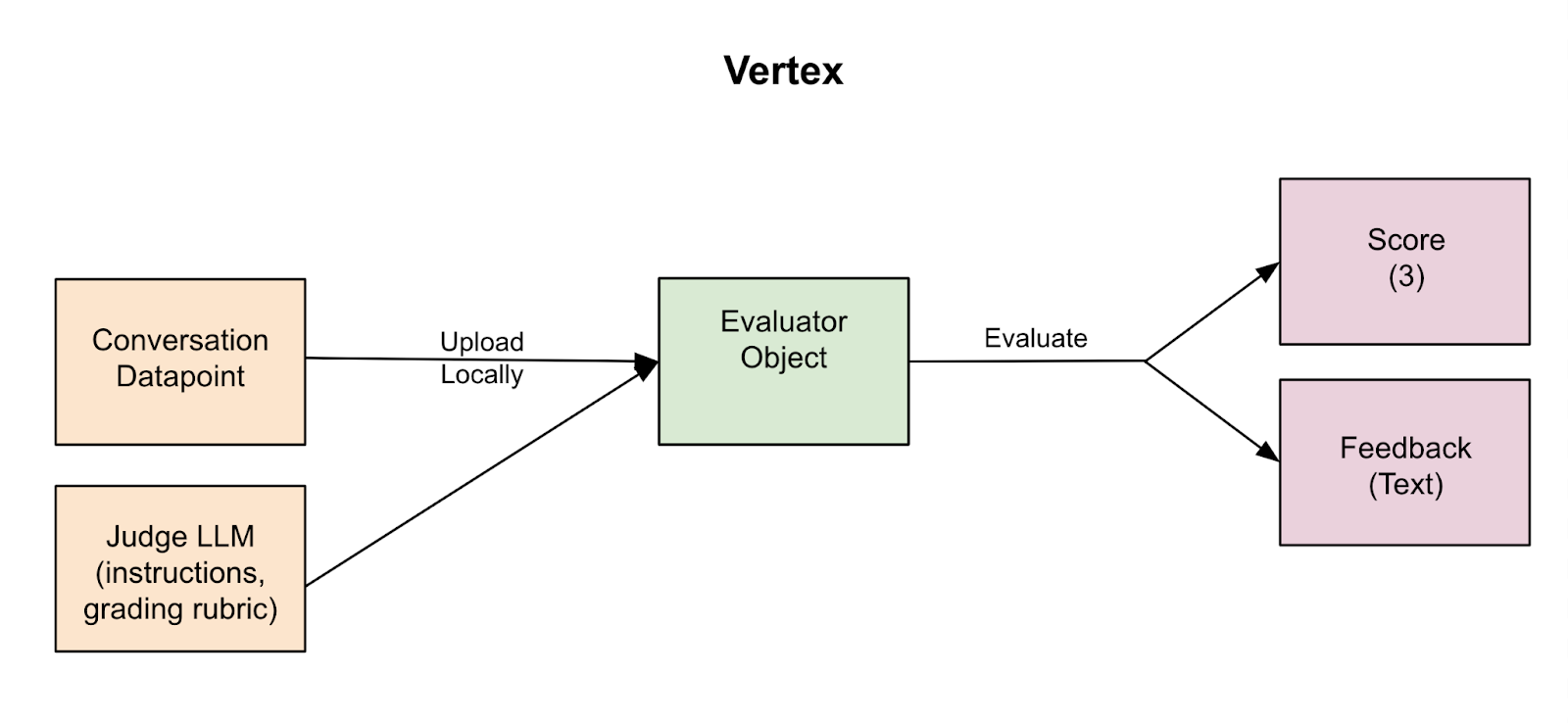
Setup: Vertex supports prompt management via its UI and Python SDK, with datasets uploaded during Eval calls. Project partitions are less convenient/intuitive, as each project is exposed to not only Vertex but the entire suite of Google Cloud offerings (which is overkill for our use case).
Customization: Vertex by far offers the most customization options for evaluation. Unlike Weave and LangSmith, Vertex’s Evaluate method offers a “bring your own response” option, so I don’t have to create a dummy model workaround.
Learning Curve: Setting up an Eval prototype took me nearly three times longer than with Weave or LangSmith. In particular, navigating Google’s permissions and tutorials proved challenging, requiring additional setup like installing the Google Cloud SDK.
UI: While the Python SDK offers advanced functionality, Vertex’s UI lacks critical features for viewing individual Eval traces, making it unsuitable for our use case. Additionally, it lacks other “nice to have” features like customizable columns, renaming options, and note fields available in other platforms.

Pricing
Vertex uses a pay-as-you-go model under Google Cloud (we also use Cloud Firestore for our data). Though I don’t know the exact rates, prompt management and storing Eval results appear to be inexpensive and almost certainly much less per month than Weave or LangSmith’s paid options at our expected scale for the near term future. Costs primarily come from LLM usage (e.g., calling Gemini models) and using Python environments like Colab.
Verdict
Overall, Vertex and Google Cloud have many features and integrations to offer, but it comes across as a “jack of all trades, master of none”, and critically doesn’t have the features we need to support our use case for investigating individual datapoints.
Conclusion
I am choosing Weave since it supports all the features we want, it was the easiest to develop on, and using the dummy model workaround to get the Evaluate method to work is not so bad. LangSmith is a close second, but was slightly less comfortable to use and develop with. While I felt that the Python SDK for Vertex had significantly better/more advanced functionality than Weave or LangSmith, ultimately the UI lacking critical data and functionality makes using it untenable. The significant extra development time (compared to LangSmith/Weave) due to complex Google API permissions and complex tutorials was also a major consideration

If I missed something or got something wrong, let me know! After all, there is so much that these packages offer and not enough time for me to explore and understand it all. What’s your favorite Eval package for LLM applications, and why?